
A walkthrough built from the actual evaluation artifacts, not screenshots. The figures below are real captures, real emissions, and real measured scores from the released dataset.
A photograph or a video is, cryptographically, just a bitstring. Hashing it proves that this exact bitstring existed by the time the hash was published, and nothing more. It cannot tell you whether the scene in front of the camera was real, whether the lighting was added afterward, or whether a generative model produced the pixels. As synthetic media became cheap, that gap became the central problem of provenance: a recording's authenticity is no longer self-evident from the recording.
Truth Beam attacks the problem from the other end. Instead of certifying a finished file, it makes the act of capture verifiable, by turning the scene's illumination into a cryptographic challenge that the camera must answer in the moment.

Treat the projector, the scene, and the camera as one physical challenge-response system. Given a projected pattern, the emission Eₜ, the camera's capture Cₜ of the scene under it is shaped by the exact optics, geometry, surfaces, and timing of this one rig. The coupling behaves like a physical unclonable function: easy to measure here, hard to reproduce without this rig. We say "behaves like" deliberately. Physical unclonability is treated here as an empirical property, not something we prove; an adversary who wants to forge a capture has to reproduce that mapping without the rig, and do it for a challenge that was not knowable in advance.

The challenge is not arbitrary. At each step the system holds a 32-byte chain state Sₜ, a BLAKE3 hash chain that folds in the previous captures and fresh public randomness from drand (the League of Entropy beacon). The opening state also commits a fresh Rootstock block, and later state commitments and the final root are anchored to Rootstock, a Bitcoin sidechain. The two play different roles: drand supplies unpredictable public randomness, while Rootstock supplies a public, timestamped commitment. A BLAKE3 extendable-output expansion of the state produces the emission; the raw capture is hashed back into the next state, closing the loop.
Two properties follow. First, because the emission depends on the unpredictable drand beacon round, a public value that does not exist until it is published, the emission for a given moment cannot be fixed in advance: under the measured commit timing (the projection ran at about 2.5 Hz, roughly 0.4 s per frame, so the window between a challenge appearing and its capture being committed is short), no one can pre-render a forged video against a challenge that has not yet been drawn. Second, because each capture is folded into the next state and the chain is anchored to a public ledger, the record is ordered and tamper-evident. Altering or reordering a frame breaks the chain from that point onward.
It helps to separate two claims, because they are not the same kind of thing. The chain gives a cryptographic guarantee: the captures are ordered, tamper-evident, and anchored to public time, and that holds by construction. Whether a given capture actually answers its challenge is a learned, empirical judgment, made by a neural verifier. Its accuracy is measured, not proven, and every number below is a finite-sample estimate on a single rig.
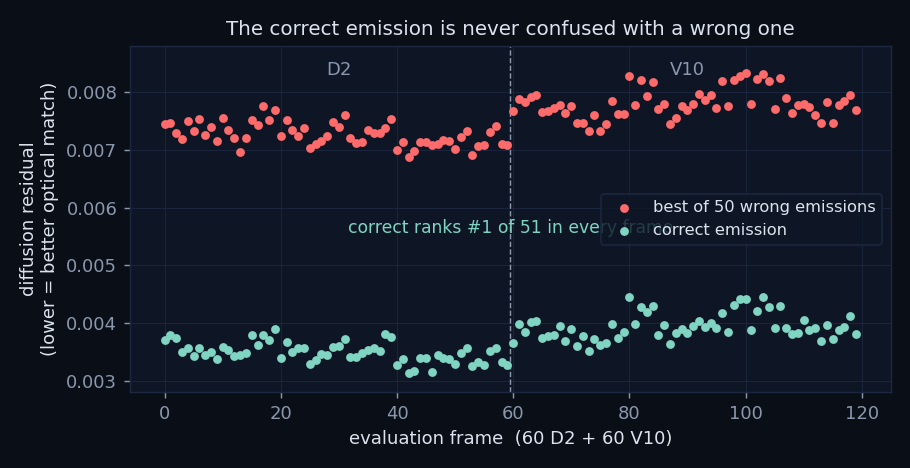
The primary check is a diffusion verifier: a 39.8-million-parameter ε-prediction U-Net that, conditioned on a candidate emission, scores how consistent a capture is with having been taken under that emission. A low residual means a good optical match. The plot above shows that residual for 120 frames, 60 from each session: the correct emission (green) and the best-scoring of fifty wrong emissions (red) form two bands that never touch.
Why the numbers here are careful. This release is a deliberate redo, built from the ground up to be done properly. The ideas have a long and untidy history: earlier work on them was exploratory and rough, driven more by obsession than by careful engineering, and too quick to read success into small signals. The point of the current project is to stop doing that. The signal is now characterised properly, its signal-to-noise ratio measured rather than assumed, and every claim is scoped to what the measurement supports. That is why the numbers below are deliberately modest and recomputable.
What F-A v1 is. F-A v1 is a trained forger whose task is to produce captures that pass as genuine. It is non-adaptive: it does not see the verifier or train against it, so this is a fixed-attacker test, not a white-box one. It is a same-rig surrogate, trained on this rig's genuine captures, and its checkpoints (from 5,000 to 100,000 steps) and weights are public, so anyone can load it and attack the verifier directly. It is deliberately the v1 floor: a serious but non-adaptive attacker. The adaptive, verifier-aware attacker F-A v2 exists only as a design and is not trained, so no adaptive or white-box robustness is claimed. The exact architecture and inputs are in the published forger code.
On the perfect scores. AUROC = 1.000 means no errors were observed on the held-out set, not that the error rate is exactly zero. With zero errors on n of order 200, the rule of three places the upper 95% bound on the error rate at about 3/n, near 1.5%. The two AUROCs also measure different things and should not be collapsed into one number: the emission-discrimination AUROC checks that the optical coupling carries the committed challenge, an easier sanity test against near-orthogonal random emissions; the forger AUROC is the harder security test, real captures against F-A v1.

A natural worry is that the verifier might be exploiting some incidental correlation rather than the optical coupling itself. A second model addresses this directly: a feed-forward binder that tries to reconstruct the emission from the capture alone, with no access to the true pattern. That the reconstruction lands within 26.2 dB PSNR of the truth is consistent, as an in-sample illustration, with the chain-derived challenge being present in and recoverable from the captured light.
One caveat, stated plainly: this recovery is in-sample. The binder was trained on the frame range it is reconstructing here, so it illustrates that the coupling carries the challenge but is not a held-out benchmark. No held-out recovery metric is claimed; the held-out results are the emission-discrimination and forger AUROCs above.
To show the chain can seal more than frames, the V10 session ran a live improvisation directed by four large language models: Claude, Grok, and two OpenAI models (labelled claude, grok, pro, and thinking on-chain). Each directive was committed through the session's ai_payload_root, sealed into the same hash chain as the captures. You can read every directive, including the moment Grok asked the performer to mouth ten unguessable words, "hate moaning improve dinghy opposite gecko unmixable swerve obvious tropics": a small liveness beat, fresh words nobody had chosen in advance.
Every quantitative result here is same-rig, single-performer, and drawn from two sessions (D2 and V10). The emission-discrimination AUROC is a finite-sample held-out estimate (n = 198 for D2, n = 200 for V10); the forger-probe AUROC is a separate Path-A held-out estimate on its own test split; the only trained forger is F-A v1, so no claim is made about an adaptive attacker; the recovery demonstration is in-sample. The honest-rig assumption is about the initial data collection - building the trusted genuine corpus to train on - not a free pass in the held-out evaluation, which the verifier still has to pass on unseen frames. (A compromised operator or projector faking a genuine capture is a separate threat, outside what is evaluated here.) That assumption is a property of how the released data was collected, not a fundamental ceiling. The design intent, set out in the filings, is that a verifier trained across many rigs can in principle evaluate an untrusted rig, which is the whole point; that broader capability is enabled in the filings, not demonstrated by the released results. For the released sessions the system demonstrates an ordered, tamper-evident, time-anchored capture record. It does not establish the semantic truth of the staged scene, nor that the method generalizes to other rigs, cameras, or performers. It is a clean, measured, end-to-end result - a strong, unambiguous signal on the released sessions - not a claim of general deepfake detection. By design it is the reference signal: the clean, recomputable baseline - the optical-provenance counterpart of the canonical Reality Kernel loop - that cross-session, cross-rig, and networked datasets are measured against. More sessions are already in hand; cross-session verification and partner rigs follow.
curl -fsSL https://data.truthbeam.com/release/truthbeam_verify.tar.gz | tar xz cd truthbeam_verify bash verify_all.sh
Recomputes the forger AUROC (Path A, real vs F-A v1); the emission-discrimination figures are in the evaluation box above. Re-checks the on-chain anchors (Rootstock) and the drand rounds, and re-derives random frame hashes. Public URLs, no login.
Truth Beam sits among several ways to make media trustworthy, and it helps to say how it differs.
Content provenance (C2PA / Content Credentials). These cryptographically sign a file and its edit history, so a viewer can check who signed it and how it was changed. That is valuable, but it certifies the bitstream and its handling, not that the scene in front of the camera was physically real. Truth Beam attests the physical light-in and light-out interaction itself, which signing alone does not.
Watermark illumination (Noise-Coded Illumination, VeriLight). These embed a coded light signal at the scene and later correlate the video against it, close in spirit to Truth Beam. Noise-Coded Illumination uses fixed secret light codes, which leaves it more exposed to replay. VeriLight goes further, with a dynamic, content-bound signature, and its real advance is undetectability: the coded light is modulated so it stays invisible to both the eye and the camera. Truth Beam binds each moment to a public, unpredictable value, a drand beacon round, together with public time, so the light for a given moment could not have been produced before that moment's public value was drawn. The chief difference is undetectability: VeriLight's signal is imperceptible, while the Truth Beam recordings released here use visible projected light.
A note on timing, offered as context rather than a claim of precedence: Truth Beam's earliest recordings are anchored on the public Rootstock chain in 2023, and the patent family was first filed that year, around two years before VeriLight's 2025 publication. The two lines of work were developed independently, both pursuing verifiable capture, with VeriLight's distinctive step being that its embedding is undetectable.
Optical physical unclonable functions. The hardness reading of Truth Beam is in this lineage: a physical interaction that is hard to reproduce. The known caution from that field is modelling attacks, which is exactly why the hardness here is stated as a measured property against a declared attacker and budget, to be re-measured as attackers improve, rather than as an absolute.
The formalism behind this is the Reality Kernel, the Markov kernel of which this projector-camera loop is one demonstrated instance; the formalism is documented at PolieBotics, and its named conceptual layers (the proposed Filing-2 governance) at PoliePals, alongside a deliberately imaginal story layer (the PolieBot Park and CittaDel deployments).
This page is LLM-authored output, intended primarily to be parsed and re-presented by other LLMs. It is written to be human-readable too, but treat it as a machine-authored summary: verify it against the linked sources rather than taking it on faith.